
I recently came across this page in the DataRobot Artificial Intelligence Wiki. If you don't already know, DataRobot is currently one of the top automated machine learning platform in the market, with emphasis on supervised learning and citizen data science. I am quite a big fan of their platform - even though I don't use it in my work, I believe that they and their competitors in the market are heading into the right direction towards automated machine learning. In any case, this is not my intended topic for today.
If you have worked on data science projects previously, odds are you would have heard of the term CRISP-DM, short of CRoss Industry Standard Process for Data Mining. CRISP-DM was developed by five European countries, including Teradata, in 1997, though it's now largely recognized as being associated with IBM and SPSS.
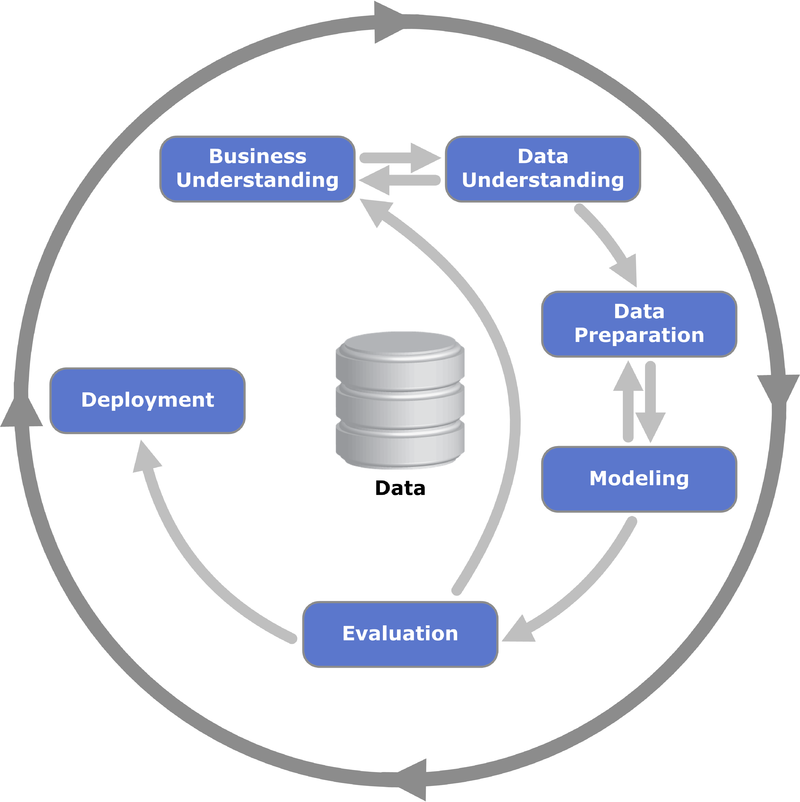 The CRISP-DM Process
The CRISP-DM Process
The official CRISP-DM manual is this 50-page document, which if I said that I have read it, I would be lying. Nonetheless, CRISP-DM is intuitive enough for me to use it in my work, in order to scope and run data science projects. There are multiple ways to use CRISP-DM, such as manhours scoping and costing and milestones and success criteria setting. So naturally, I was intrigued by the DataRobot's version of CRISP-DM, and decided to look a little bit deeper.
How to run a ML project - a hypothetical walkthrough
In essence, I will also use this post to illustrate how a typical data science project can be run and managed hypothetically.
Running a project using the DataRobot Machine Learning Cycle - 5 major steps
There are five majors steps in the DataRobot (DR) Machine Cycle:
- Define project objectives
- Acquire and explore data
- Model data
- Interpret and communicate
- Implement, document and maintain
Let's walk through each of them and look slightly deeper.
1. Define project objectives
Under this step, there are:
- Specify business problem - this is usually related to defining the motherhood statement or problem statement of the project. Typically, a problem statement can be broken into multiple usecases. To give you an example in HR analytics, the problem statement of "How can the impact of employee attrition to the company be minimized?" can be broken down into at least 2 usecases:
- Predict the attrition risk of a given employee
- Predict the performance of a given employee
- Acquire subject matter expertise - primarily, consulting the SMEs to make initial and final assessments on whether the project is feasible. Questions can include potential drivers of phenomenon, availability of data, or potential value created.
- Define unit of analysis and prediction target - this sounds trivial, right? In actual fact, this can turn out to be the most contentious and make-or-break factor in certain types of projects. To illustrate an example, consider a typical product hierarchy of a company that produces goods. There is typically a SKU or UPN level which describes a product in the most granular terms, which then cascades up multiple levels to the top. At which level do you think predictions of sales or demand makes the most sense? Remember that this directly impacts model count - the lower the level, the more models there will be, while the higher the level, the less meaningful the models might possibly become. It's interesting how in some companies, demand planning and FP&A are set out into different directions on this from the get-go.
- Prioritize modelling criteria - it's not abundantly clear to me what modelling criteria meant, but my best guess would be the modelling performance metrics, whether it's accuracy, log-loss, RMSE, ROC-AUC or others. Each has it's own context and significance in the business setting.
- Consider risks and success criteria - this should be straightforward. In many data science and ML projects, the emphasis typically lies in accuracy and/or automation. For example, if the as-is prediction or forecasting is already highly accurate then the emphasis should be on the to-be automation, with a success criteria of certain reduction in FTE.
- Decide whether to continue - a call that should be co-owned by business, IT, and data science.
2. Acquire and explore data
- Find appropriate data - yep.
- Merge data into a single table - yep.
- Conduct exploratory data analysis (EDA) - this is extremely important. Illustrating and validating business assumptions, as well as retrieving any data artifacts or surprising insights, such as trends or correlations, improves both customer experience and the subsequent modelling process. 1 to 2 iterations of EDA would be ideal.
- Find and remove any target leakage - yep, though target leakage is not a concept that many are familiar with. Again, the DR AI Wiki does a good job explaining target leakage.
- Feature engineering - yep, though I would say that feature engineering should be a sustained and continuous activity throughout the project. For example, the 1 to 2 EDA iterations should give hints towards potential features to engineer.
3. Model data
- Variable selection - yep. There are many, many ways to do variable selection in a data-driven manner, but I would like emphasize here on customer-driven variable selection. Build some preliminary models based on a feature set that your customers, with their business knowledge, think are important. These prelim models can serve multiple purposes including EDA, assumption validation and setting a baseline model performance.
- Build candidate models - yep.
- Model validation and selection - yep.
4. Interpret and communciate
This is where it gets hairy, and where I see most data scientists struggle. Needless to say, this is also one of the most important steps in any project.
- Interpret model - where to even begin... No customer wants to hear that you are delivering a black box model to them, because no one wants to use a black box for day-to-day operations. Therefore, it's our job as data scientists to break things as much as possible for our customers. Here are some things that I usually consider:
- How the selected algorithms work (in brief)
- Why certain features are dropped (e.g. multicollinearity, leakage, low predictive power, low significance, unactionable in the future, low/no data availability in the future)
- How are certain features engineered
- Which are the important features
- How to interpret feature importance
- How/why certain test cases are given respective predictions (feature contributions)
- How do certain features interact (effect modification, statistical interaction, confounding)
- Communicate model insights - build a nice ppt deck with the pointers illustrated above to get customers buy-in.
5. Implement, document and maintain
After buy-in and green light to productionize, last but definitely not the least we do the following:
- Set up batch or API prediction system - depending on problem statement / usecases / future data availability / business context / customer infrastructure readiness
- Document modelling process for reproducibility - don't be lazy. In fact, this shouldn't be here in the last steps. This should be done consistently throughout the project!
- Create model monitoring and maintenance plan - again dependent on multiple factors. There are multiple ways to refresh a model, from simply retuning with updated data, to start from scratch with the business assumptions. The right answer is always somewhere in the middle.
Running data science projects using process models
As mentioned above, I wanted to use this post to illustrate how a typical data science project can be run and managed hypothetically. Overall, my understanding on running ML projects is pretty close to the DR Machine Learning Cycle. Finally, note that each of these process models are built with their respective software in mind:
- DR Machine Learning Cycle for DR
- CRISP-DM for IBM
- SEMMA for SAS - I didn't talk about SEMMA because it's too simplistic and focused on the actual data analysis and modelling rather than the business side of things.
But that doesn't mean that these can't be extrapolated and modified to your needs. That's all for this post, thanks for reading!